

In a couple of months, I will be joined for a week by a small group of amazing people, to set up the foundation for a new modular data corrections suite. Here’s some details on the what and how, but starting with the why…
Why?

The modular data corrections, as currently implemented in the Data Analysis WorkbeNch (DAWN), are in use at several locations for a few years now. For us, it has proven its worth by providing a (mostly) hassle-free, adaptable data corrections pipeline to traceably extract real value out of any measured data. The resulting reliability means we no longer fret about the correctness of our data during the analysis, greatly speeding up the data processing.
So, with this proof in hand, it is worth preparing for the future. That means reimplementing the works in Python, and making some improvements along the way. The improvements will include more extensive handling of uncertainties (and open up avenues for thorough evaluation of said uncertainties), support for units and instrumental resolution, and extending its utility to other scattering-based and imaging techniques as well, including diffraction and imaging.
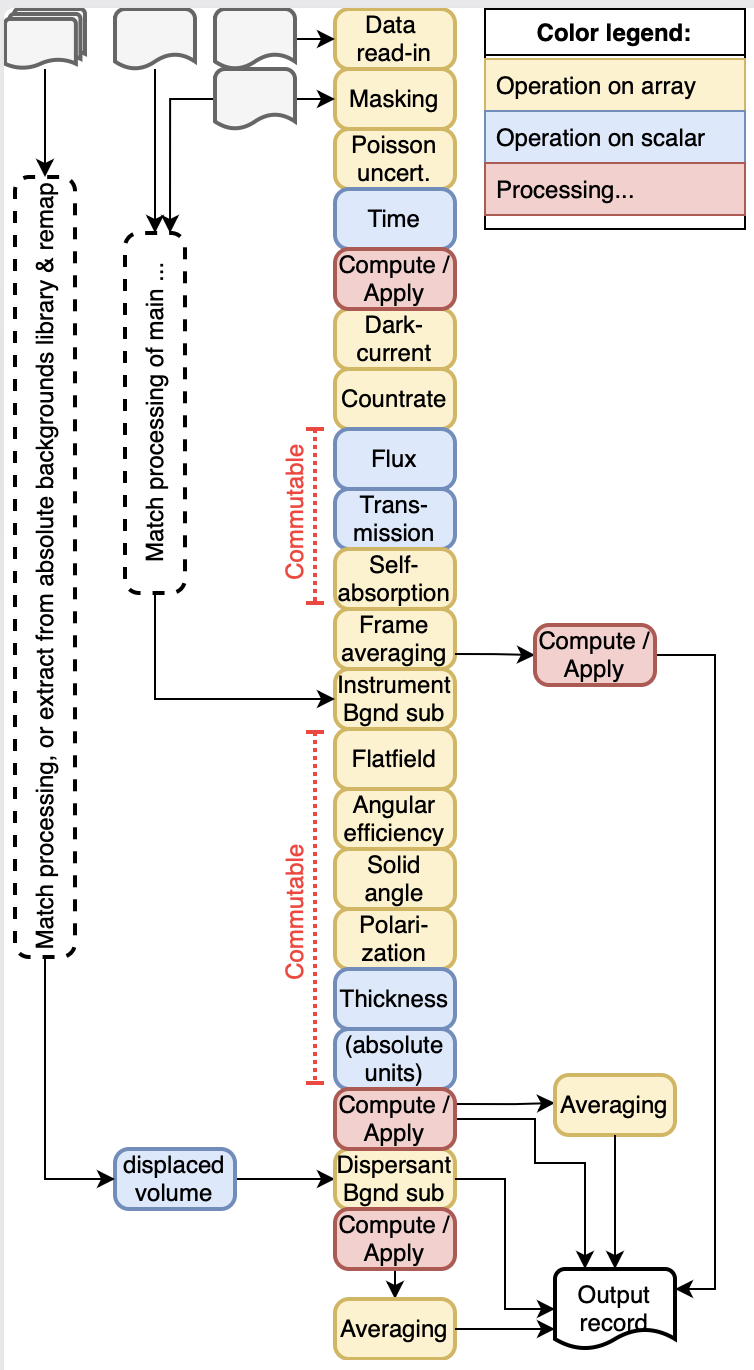
A core goal is to make this package useful to both laboratory as well as synchrotron users. That implies (amongst others) that it needs to be both easy to use for file-based working styles, but also fast and able to deal with streaming data for synchrotron uses. Eventually, a user interface might need to be added to help with this, although ideally this stuff all runs under the hood, automatically, without risk of human interference with the process.
Sounds all nice and dreamy, but how do you realise such things?
How?
My colleague and co-conspirator Tim from the Diamond Light Source and I have been talking about this for several years. During the last small-angle scattering conference in Taiwan, we therefore amalgamated a few interested parties and tried to hash out some ideas and a project scope to get started.
Currently, the project scope approximates as: “developing a performant, future-ready, python-based data corrections library for X-ray and neutron data that will improve on previous approaches. It will add support for units, adaptable uncertainty estimation, and smearing/resolution, supported by a fast framework capable of dealing with file- and stream-based data”
With that scope in place, we started refining the ideas a bit over subsequent walk-and-talk meetings, a few zoom calls and many e-mail exchanges with various stakeholders.

We figured we have a lot of different aspects to cover, and so decided to bring together a small collection of ten-ish people with very specific skill-sets that could mesh well in a one-week hackathon. We have collected lab- and synchrotron data specialists, scientific software programmers with specialties in high-performance computing, and a few specialists from industrial partners with a vested interest.
The work so far..
If we want to do this right, that means planning and careful assembly of the foundation on which the whole project rests. The choices there will have an enormous impact on how the entire package will perform, and how convenient it will be to program the individual correction modules.
We’ve been doing some preliminary work since the last few weeks in preparation for the hackathon, for example by checking if we can leverage the following existing packages:
- attrs for defining the dataclasses and adding the boilerplate, input and type checks
- Tiled as an interface for file- and stream-based I/O
- Dask for easy parallelisation with an optional exploitation of GPU acceleration, e.g. through PyTorch
- PyFAI for fast averaging operations
- Pint for unit conversions, which can be applied when loading data, and when converting to display values. Internally, SI standard units will be used throughout so that unit conversions are avoided.
- maybe XArray if it is beneficial from a cost/benefit perspective, but at the moment we are not sure it brings sufficient advantages. We’ve also been considering Scipp and SciLine.
We’ve opened a GitHub repository for this collaborative effort, complete with wiki for documentation and an issue tracker for discussions. It’s still mostly just a template at the moment, but I expect this to develop rapidly during the work in May.
The work coming up..
But there are a host of additional options and considerations to be done, which will be explored and (hopefully) decided on in the week in May. We want to do test-driven development for this project, which puts a heavy emphasis on developing good tests, adding in-depth profiling and writing and drawing the accompanying documentation.
As always, we will keep you updated with the progress, especially during the week. Once we have the foundation, some tests and a template for a correction module, it will be time to start building up libraries of corrections, which will hopefully be heaps of fun!