

Earlier this year ago, we hosted the first code camp to lay the foundations of the Modular Data Corrections (MoDaCor) python library. Amidst almost continuous, engaging discussions on scattering, we also made good progress on the codebase. Here is what we managed, and what we’re trying to achieve:
The Goal
The MoDaCor project set out to answer the need for a good, universal modular data corrections library, that is able to generate high-quality data. High-quality data is, of course, traceable data with well-founded uncertainty estimates, corrected to the best of one’s abilities. Standardising on a particular library of data corrections would eliminate this particular source of inter-laboratory variance, which, in turn, will improve the (inter-laboratory) reproducibility of our science.
The Challenge
Data correction can be done by most scattering and diffraction software to some extent, with greatly varying levels of thoroughness. It is not immediately evident whether these (partial) corrections are sufficient for a given sample, and what effect any incompleteness would have on the result. To check that effect, we would need to check this partially corrected data (and the outcome of its analysis) against data corrected to the full extent.
Once we have the full correction pipeline available, we also have the option, if needed, to balance performance against the needs. In other words: if we need faster performance, we can make well-founded decisions on what corrections can be omitted for a known amount of signal quality loss.
We believe that it is possible to create a correction suite that:
- is flexible and adaptable to a range of instruments and techniques (monochromatic scattering & imaging)
- has a fully traceable effect on the data
- propagates (multiple) uncertainty estimators in a pragmatic way, whose performance can be compared against other estimators (e.g. Monte Carlo-based uncertainty estimation).
- handles units
- yet still has a reasonable performance even when working with the full set.
The people
A good number of interested parties/stakeholders have shown interest in the outcome, and we were fortunate to have a few of them join us for a week in May to help get this show on the road. Among them were contributors from BAM, the Diamond Light Source, ESRF, DESY and Anton Paar. Several other partners have also expressed interest in the package, but could not attend in person.
The Plan
In very rough terms: the initial plan is to:
- get a rudimentary foundation up and running with a pipeline engine and data handling
- then start churning out a set of correction modules,
- after which we can make a full correction pipeline for scattering data,
- start investigating the effect of each step on the data and its uncertainty estimates
- Finally, we want to check the quality of the uncertainty estimates, comparing the propagated uncertainties to other methods of estimation, such as Monte-Carlo-based estimation.
We’re still far from that, though, and first need to get the rudimentary library working. There are some details to consider for this:
Basedata: the core quantum of data
The set-up
We needed a dataclass to carry an array of data, along with some essential metadata (units, uncertainties, etc). BaseData does just that, and can be used for an intensity matrix, or a Q matrix, for example. This BaseData has a few peculiarities, in particular the following:
Arrays and scalars
What we want to obtain from the analysis of scattering data in particular, is to get two bits of information, 1: shape, size or structure information, and 2: volume fractions. While the shape or size information only comes from fitting the curve or image data, (and therefore would work with the inter-datapoint uncertainties), the volume fraction also needs information on the absolute scale of the data. The uncertainty on the absolute scaling can easily be an order of magnitude larger than the inter-datapoint uncertainty (due to large imprecision in the thickness determination, for example), and the two should ideally not be mixed.
I have just had a long conversation with our in-house statisticians, however. While they initially agreed that it is good to keep scaling uncertainties separate, it may not be possible to do so in this case. One example where it would not work is if you follow a scaling operation on your array, with a per-pixel adjustment afterwards (e.g. if you normalise by time, followed by a countrate correction). In that case, the single uncertainty on your scaling operation affects the per-pixel uncertainty of the subsequent operation. If so, this would put a much increased requirement on the accuracy and precision of the scalar metadata.
Supporting multiple uncertainty estimators
At the start of our correction sequence, we may only have one uncertainty estimator on our data, i.e. the uncertainty on each pixel based on the photon-counting statistics on each detected number of counts.
During the correction, however, we may be able to get additional estimators. These could be obtained, for example, during dimensionality reduction operations such as averaging along a dimension. In that case, we would not just get the mean of the value, but also a measure of the variance (standard deviation and standard error on the mean) between all averaged data. Likewise, you might want to add a minimum estimator at some point, based for example on the noise floor of the detector or by simply saying “I don’t think I have uncertainties smaller than 1% of the value”.
During the pipeline, you may want to propagate these different estimators separately, so we are implementing our uncertainties/variances as dictionaries. That will allow one to add a new estimator if needed at any point in the pipeline.
Support for units
One of the banes of our existence is the common usage of several units. The ability to handle units makes it possible for us to adapt the output to the preferred flavour, and to ensure consistent units are used in the operations. It adds a little work to the BaseData class, but it is an almost negligible overhead in all steps apart from the data ingestion and output steps
Pipeline handling
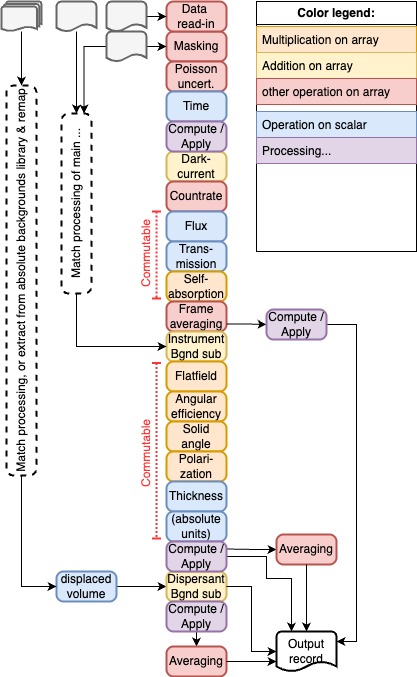
Because the exact sequence of corrections may be method- or even instrument-specific, a data corrections library needs to be flexible in the order of operations. For each method, one would need to set up a best practices correction workflow or data pipeline, which can then be fine-tuned to adjust to the peculiarities of a given instrument. These pipelines form a graph, which, to make things more complicated, can combine and split off branches as well (see example on the left). Not the easiest task, but with the experience of several of our contributors and some Python libraries, this is taking shape nicely and a prototype runner seems to be functional.
Dealing with I/O
I was hoping to exploit bluesky’s Tiled library for I/O, as it provides a unified interface for accessing data across a range of files and data systems. However, we found it not quite ready yet, in particular with some remaining performance issues to be resolved for local operation.
Therefore, we implemented a very lightweight interface called IoSources for now, that allows us to access data from a range of sources (including Tiled) in the same way. IoSources is a collection of IoSource objects, which can (for now) be an HDF5Loader, or a YamlLoader. You can then refer to data like:
some_hdf_file::/entry1/instrument/detector00/dataor (loaded from a nested structure in a YAML file):
defaults::/em_properties/wavelength/uncertaintyYou can register as many separate data sources as you need, and this should be easily adaptable to Tiled once that matures a little more.
Project set-up
We’ve set up programming guidelines as well as a CI/CD pipeline for the project on Github with a small test suite included (here). Contributions can be made using pull requests. While the project is currently enjoying a holiday slump, this should pick up again once I’ve returned properly, and once some other tasks are cleared off my desk again. Firstly I need to figure out to what degree to implement the uncertainties handling for now. Given its modular nature, this can be upgraded at a later stage, but a reasonably pragmatic working version should be in place before programming too many modules. After that, I/O and pipeline handling should be finalised so we can do the first read-process-write cycles. And then we’re ready to take over the world.