

By now, we have developed a quite extensive data processing pipeline whilst maintaining a high rate of samples on the MOUSE instrument. To stave off the tedium that comes from running the data processing steps, while providing more flexibility on what is run, and to make it easier to maintain and update the processing workflows, we have installed RunDeck to help. Let me clarify..
Like many of you, we have created a series of command-line scripts over the years to help process our data. These include:
- checkFileExistence Checks whether all the necessary files exist by YMD
- proposalUpload Upload the proposal by YMD to SciCat
- structurize Structurizes measurements by YMD
- AutoThickness Calculates the thickness based on the transmission and the stored X-ray absorption coefficient.
- UploadRaw Uploads the structurized measurements by YMD
- correctWithDAWN Corrects measurements by YMD
- UploadProcessed Uploads the corrected measurements by YMD to SciCat
- datamerge Automatically merges data from all groups by YMD into a single file
- UploadMerged Upload merged data to SciCat by YMD
- mergedToDat Automatically converts merged nexus files to dat by YMD for ASCII afficionados
- doAll Does the entire processing chain for a given YMD measurement date:
- AutoMcSAS3 [experimental] Do a quick McSAS3 run for automatic size distribution analysis
- update python things on server
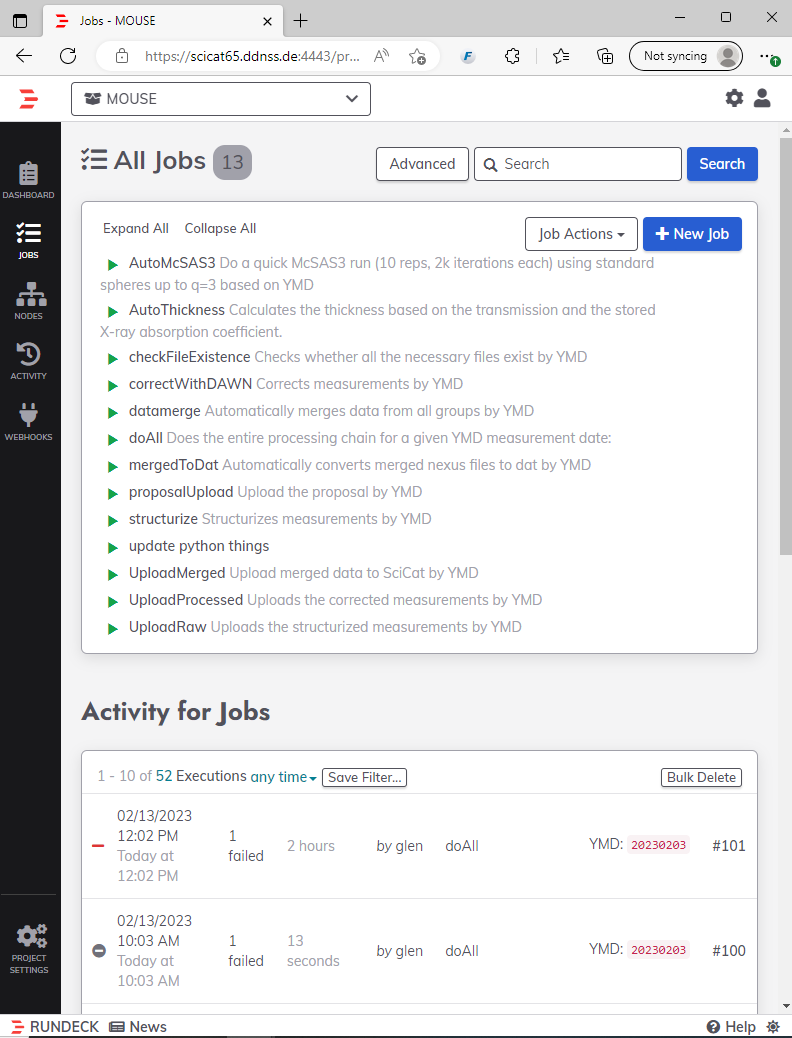
This eclectic mix of shell scripts and Python scripts is normally run in sequence for a given measurement series (defined by their measurement date, YMD or year-month-day, which is used mostly as UID for a series and normally matches the starting date of the series). When it all runs well, we automatically end up with merged, corrected data in absolute units from multiple instrument configurations.
Sometimes this works, sometimes it doesn’t. It is a complex system with many parts, we are but a few, and the correct functioning requires correct details to be filled in into our electronic logbook. We regularly need to update the input and then redo particular step(s), and if this is done with shell scripts and text configuration files, it creates a barrier that makes it more likely that such things fall by the wayside. I suspect we scientists are very allergic to the even the slightest hint of tedium.
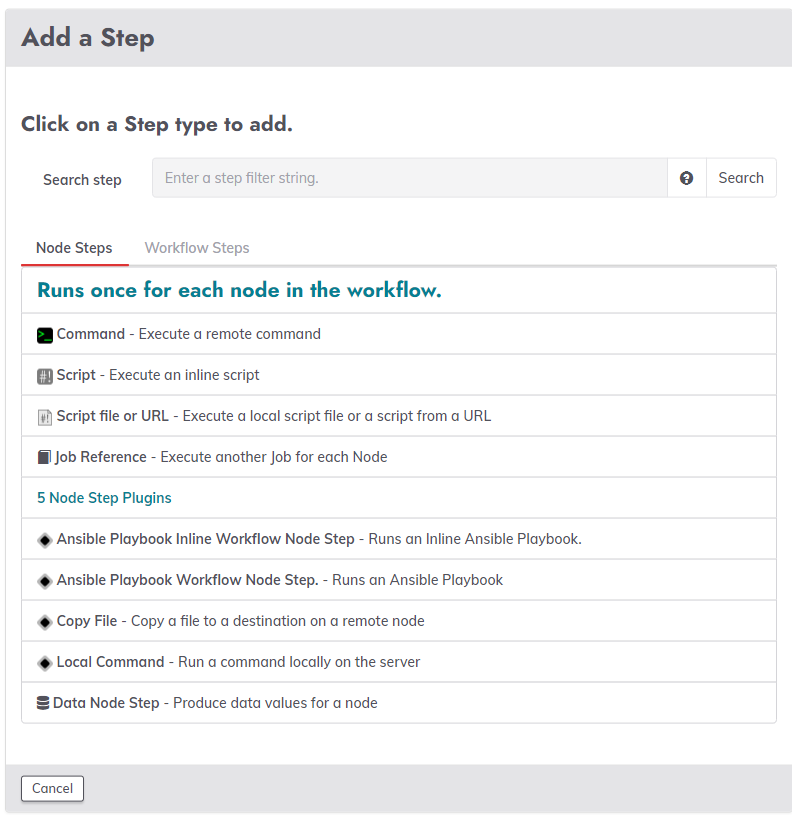
This is where RunDeck comes in. It’s a simple service that can be installed without much fuss on an internal server. In its fancy user interface, you can set up tasks and small scripts, and (for example in the above case of “doAll”, sequence these smaller tasks together into a larger workflow.
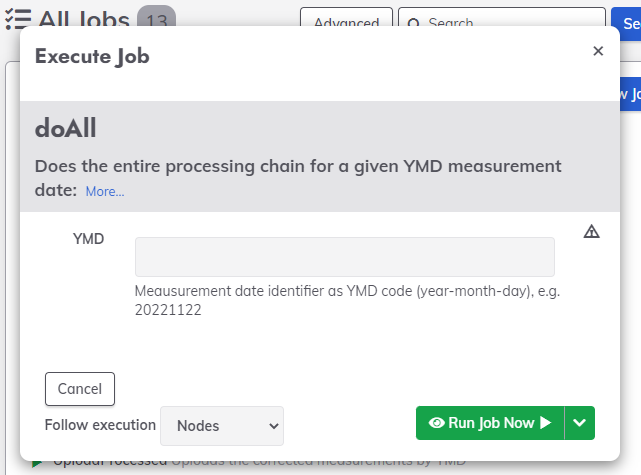
RunDeck then provides a web interface from which these steps or workflows can be run (or in the case you have the luxury of multiple nodes, can be submitted to nodes). You can have the workflows run automatically or by hand.
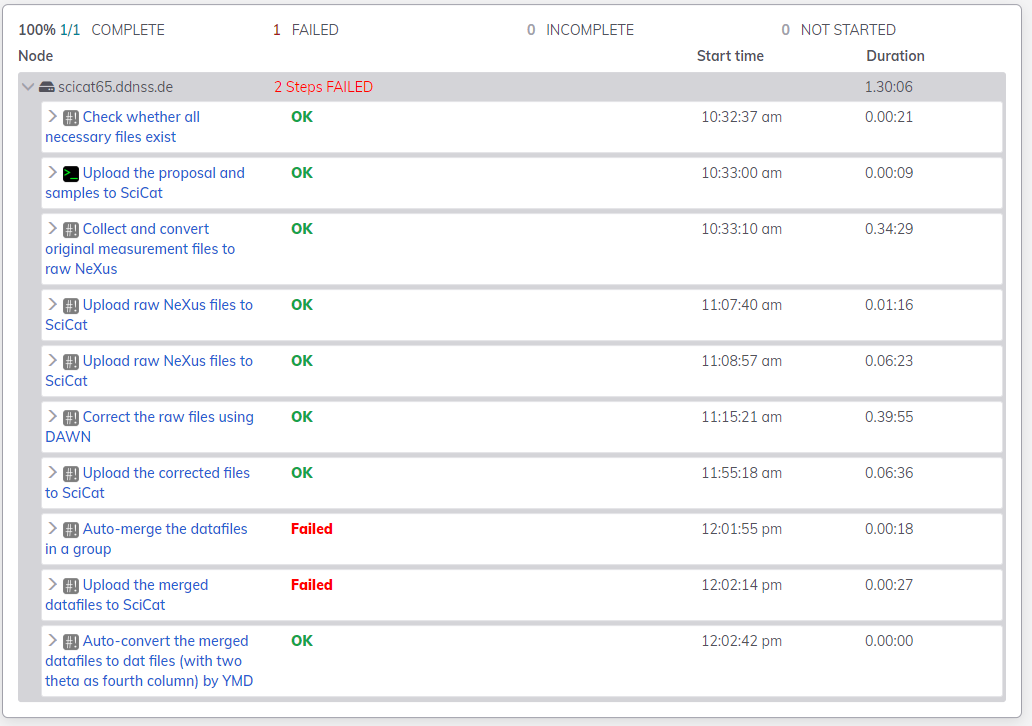
So far, it might not sound like a step forward over teaching someone how to use the terminal, but it has several advantages:
- Clicky web interfaces with a modicum of graphics reduce the barrier to use for a cross-section of users, compared to starting scripts from a terminal.
- Since the processes now run from the “rundeck” user, not everyone needs a separate shell account anymore or needs to install their own python codebase with associated libraries (advanced UAC is available from within RunDeck instead if you want fine-grained permissions).
- If a workflow or step went wrong, I can call up the log from that particular run and that particular step. This is perhaps the biggest advantage and is super powerful for debugging.
- Increasing granularity is no longer counterbalanced by users having to remember an expanding list of commands to execute.
- Steps or workflows can be separated by project for clarity. This way, it is clear what commands are available for which type of work.
So while the functionality of RunDeck initially seemed redundant, the ease of use of the interface has been welcomed by both me and Glen. Future advantages include distributing the workload over multiple nodes via webhooks, and automatically launching workflows upon completion of a measurement series.
To all the instrument scientists and managers out there: perhaps give this thing a glance, it might just simplify your work a little. Big thanks to my partner for highlighting its existence and capabilities and encouraging us to install this over some of the more involved systems (e.g. Jenkins, Airflow, etc.). Thanks to Ingo for taking the time to install it on our processing server.
Leave a Reply