

Our first-time-ever trial run of the “Better with SAXS”-course was — on the whole — a nice success. Here’s the details:
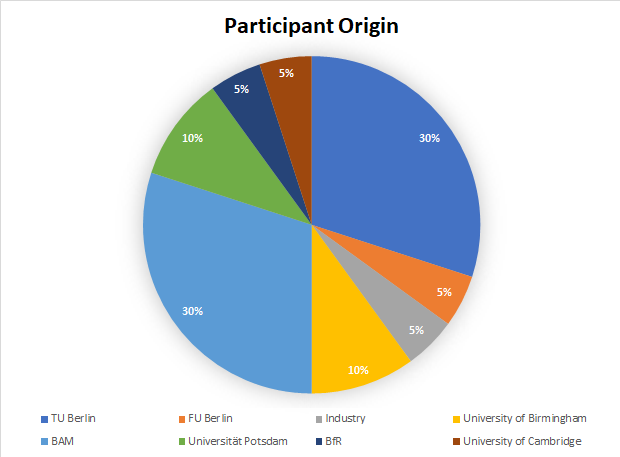
The course was set up to run over four days, with the fourth day as a “bonus” day. Every day consisted of lectures in the morning and a more practical segment in the afternoon (and a table-soccer segment in the breaks for those interested in that). About 20 participants were coming in total, from various places around Berlin (see Figure 1), and some even joining in from Birmingham and Cambridge. For each participant, data was measured on their specific sample so they would have that little bit of extra benefit from the course. This did mean that the MAUS was blocked with samples for the course for about four weeks, and some datasets would’ve been better without the time pressure. Still, pretty good data for everyone meant that the participants could assess for themselves what they could stand to gain by including scattering into their spectrum of investigative techniques.
On the first day, the participants were introduced to the method by Andreas Thünemann, received a lecture on Fourier Transforms by me (with some demos) and the data correction background and pipeline by Tim Snow from the Diamond Light Source. Glen Smales made sure that we didn’t dive too deep into the gritty details of the corrections, which was appreciated by all. Punctuating the afternoon was a remote lecture by Martin Hollamby, who talked about the cases where he applied scattering to get insight into his material science projects. Apropos, the remote lecture went well, saved several hundred kgs of CO₂, and meant that Martin could contribute without putting extra strain on his family. We’ll be exploring this further in the future!
The second day, Glen talked about how he used scattering to follow the synthesis pathway of his MOFs during his Ph.D. project, while Andrew Smith introduced the i22 SAXS beamline and its capabilities. After this, Glen explained how we do the data corrections for the data from our big laboratory instrument (the “MAUS”) followed by a visit of the real thing. Participants were then able to work in the afternoon on correcting and combining their own datasets. The little Jupyter notebook script I had written to merge the datasets from different sample-to-detector differences, however, only worked with about half of the people. Fortunately, there were pre-corrected datasets to hand to the participants to work with on the third day. We finished day 2 with an initial look at everyone’s datasets, where we identified the interesting points in the data and what they might tell us.
The third day was filled with lectures on data analysis software. Ingo Breßler talked about his work on SASfit, the classical least-squares fitting package sporting a very wide range of models and an easy methodology for combining models. I then talked about McSAS and what it could do for some of the projects we’ve applied it to, with Tim showing off the SasView 5.0 capabilities. The participants were then left to try out some of these programs on either the demonstration datasets we used, or their own data. Naturally, we walked around giving tips and advice for which models and fitting programs might suit their samples best. Having three programmers of the three packages running around was, of course, somewhat of a benefit there.
Day four, the “bonus” day was intended for the participants who wanted a bit more advice on their data, with about 50% of the participants staying for this day. This turned out to be very useful for them with many leaving with much better models to fit their data than they got at the end of day three.
Over the entire course, we had exemplary support from our administrative staff, a nice meeting room with a good view, and excellent lunches. The participants left happy, with only a few points of improvement indicated. For next time we will probably include a day more at the beginning to get absolute beginners up to speed, with the participants with a bit more experience joining on day 2. We’ve learned a great deal from the course, the participants and their samples too, so it’s a win-win for all.
After the course, though, it was high time for a decent rest for all of us. The next course will probably be around the same time next year. See you there, perhaps?
Leave a Reply